

Making Everyone's Vote Count: Computer Detection of Gerrymandering
Making Everyone’s Vote Count: Novel Mathematical and Computational Algorithms to Detect Gerrymandering and Create Fair Voting Districts
Kyle Gatesman
Thomas Jefferson High School for Science and Technology
This paper was originally included in the 2018 print publication of Teknos Science Journal.
Abstract
Gerrymandering is the act of purposely constructing voting districts which favor a particular electoral outcome. A powerful strategy for gerrymandering involves “packing” opposition voters into districts in a manner which wastes the votes of opposition supporter. Here I study the effectiveness of different packing strategies using realistic lattice models of voter distributions. I first demonstrate that packing gerrymandering strategies which do not include geometric data generically lead to (legally prohibited) disconnected districts. Subsequently, I construct modified packing algorithms which incorporate geometric data in order to construct aggressively gerrymandered, equal-population, connected districts. These algorithms are used to generate large sets of valid gerrymandered territories. Through statistical studies on sets of gerrymandered territories, I quantify the impact of gerrymandering on electoral outcomes. Furthermore, I argue that aggressively gerrymandered territories generally fail isoperimetric quotient tests and thus my results provide quantitative support for implementing compactness tests in real-world political redistricting. Finally, I end by discussing the extension of this gerrymandering optimization research in my development of a fair districting algorithm.
Representative democracies must necessarily group constituents into voting districts by partitioning larger geographical territories. In the United States the power to draw district lines within a state belongs to the state legislature or districting commission. Thus, self-interested politicians with this authority could gerrymander – manipulate the district lines of their territory – to maximize the electoral outcome for their own party. Gerrymandering for political gain is morally questionable as it reduces the power of the electorate, and this practice is not restricted to any political party or country. Indeed, the Supreme Court of the Untied States is currently hearing two gerrymandering cases, the first Whitford v. Gill (2016) concerns the 2011 redistricting plan for Wisconsin due to Republican legislators, and the second Benisek v. Lamone (2017) is regarding changes made to the boundaries of Maryland’s 6th district by the Democratic Party. Furthermore, in principle, there are instances in which elaborate redistricting could be with applied with benevolent intent, such as ensuring the proper representation of minority groups (based on ethnicity, religion, or other identifiers) which are not spatially localized. Such majority-minority districts have also been the focus of Supreme Court hearings, e.g. Shaw v. Reno (1993) and Miller v. Johnson (1995). Political gerrymanderers aim to maximize the number of districts in which constituents of an opposing party will assuredly lose the majority vote, thereby minimizing the opponent’s political influence. However, districts are commonly required to conform to certain general requirements:
Connectedness: Each district must comprise a single, connected region.
Uniformity: All districts in a territory must have approximately equal populations.
Shape: Districts should be generally compact, but legal stipulation is limited.

Figure 1: A sample 5 × 5 territory, with two different gerrymandering approaches.
Despite these requirements, clever redistricting can have significant consequences. Consider an election involving two parties, which I label red and blue, and a territory which can be modeled as a 5 × 5 grid. Each of the 25 unit squares denotes a territorial unit, and its color represents the overall party affiliation of its voters. For the purpose of this simple example, I will assume a uniform population (thus each unit has equal voting weight) and a voter preference such that 60% (40%) of the units favor red (blue). Given the split in voter preference, an impartial districting into five districts should be expected to yield three red-majority districts and two blue-majority districts. However, as illustrated in Figure 1, it is possible for the blue party to gerrymander the territory so that it wins three out of the five districts, thereby winning a majority of districts. Conversely, the red party can construct four red-majority districts instead of three.
There is a sizable body of existing literature which focuses on minimizing, optimizing, and detecting gerrymandering. Of particular note, several groups have proposed methods to construct fair districts e.g. Sherstyuk (1998); Altman & McDonald (2011); Puppe & Tasnadi (2015) (which are population equal and non-partisan) or maximally gerrymandered e.g. Friedman & Holden (2008); Puppe & Tasnadi (2009); Apollonioa et al. (2009) (which favor a particular outcome). Additionally, Polsby & Popper (1991); Roeck (1961); Schwartzberg (1966); Young (1988); Chambers & Miller (2010); Hodge-Marshall-Patterson (2010); Oxtoby (1977); Niemi et al. (1990) presented a range of geometric tests, such as voting district compactness and convexity, to detect gerrymandering, but these typically do not account for non-uniform population distributions. In particular, an influential paper of Friedman & Holden (2008) (FH) systematically explored methods of “packing” and “cracking” voters into districts, arriving at the mantra “sometimes pack, but never crack”, and propose a packing procedure for strategically gerrymandering a territory. Despite providing a number of excellent insights, the gerrymandering algorithm proposed in Friedman & Holden (2008) entirely neglects the spatial distribution of voters and thus generally leads to highly disconnected voting districts.
Specifically, in this work I develop a lattice model which encodes population distributions and voter preferences. Using this lattice model, I study the spatial profile of the aggressive gerrymandering strategy outlined in Friedman & Holden (2008). I show that the method of Friedman & Holden (2008) generally leads to disconnected districts. Subsequently, the main pursuit of this work will be to construct an algorithm which takes a voter distribution on a lattice and returns valid gerrymandered redistricting with a given number of equal-population, connected districts. To my knowledge, such a lattice model of gerrymandering is absent from the current literature. However, lattice studies of redistricting can clearly provide a great deal of insight. I then use my model to quantify some general statements concerning gerrymandering. Here I use my lattice population models to compare gerrymandered districts to geometrically constructed ‘fair’ districts and examine how this changes the net vote in each district and the overall election result, in order to quantify to what extent gerrymandering is advantageous to the proponent party. Moreover, by applying common measures of gerrymandering to the districts generated via my algorithm, I will be able to provide a quantitative assessment of whether these measures can detect and potentially constrain gerrymandering. I show that for realistic distributions of voters, aggressively gerrymandered districts (generated from the algorithm developed here) generally fail isoperimetric quotient tests.
Specifically, I will consider two distinct packing strategies:
Saturation packing: The gerrymanderer constructs a small number of districts predominantly comprised of opposition voters. This skews the partisan bias in the remaining districts, and improves the gerrymander’s parties’ chance of electoral dominance.
FH packing: The gerrymanderer forms districts of the most partisan voters from both parties, with a bias such that each district favors the gerrymander’s party. The last district(s) however must be comprised of moderate voters with an opposition bias.
In the saturation strategy the gerrymanderer constructs districts to be discarded, whereas in FH packing the gerrymander expects to lose the last (moderate) districts. While the latter approach is more refined, it is computationally less tractable Puppe & Tasnadi (2009) and, as I show, is significantly less effective once constrained by spatial data.
This work is structured as follows: In Section 1, I outline a procedure for generating lattice models of population and voter distributions. In Section 2 I outline a specific model of aggressive gerrymandering, proposed by Friedman & Holden (2008), and using my lattice models I demonstrate that this leads to disjointed districts. Subsequently, in Section 3, I outline two packing algorithms, one of which is based on similar principles to Friedman and Holden’s approach, and both of which take into account spatial information regarding voters. Finally, in Section 4, I give a summary of results, a discussion of their implications, and suggest potential directions for subsequent studies. Python codes which implement the algorithms discussed herein are provided in the supplementary materials.
Modeling Voter Distributions on Lattices
A manner of generating large sets of quasi-random population and voter distributions can provide a flexible tool for studying the general features of population subdivisions and gerrymandering. Abstracting away from purely data-driven studies of voters distributions can allow both more general studies and more specialized studies depending on how one implements the model. In this section I outline an elegant manner of implementing a quasi-voter population distribution. Specifically, I propose to study a population distribution which is modeled on a binomial distribution (generated by a walker algorithm), which well approximates a discretized Gaussian distribution with random fluctuations. Such a quasi-Gaussian distribution well approximates a city or town in the absence of natural boundaries (which breaks the spherical symmetry). I then superimpose a spread of partisan bias on this population, as I describe below.
Lattice Models of Population Distributions
I begin by defining the key concepts which occur throughout this work.
Definition 1
A territory is a set S = of voters v ∈ (−1,1). The total population of the territory is the cardinality PS := |S|.
Definition 2
A territorial unit T = is a subset of the territory T ⊂ S such that S = ∪iTi. and Ti ∩Tj = ∅ for i ≠ j. The population in a given territorial unit is PT := |T|.
Definition 3
A district is a union of territorial units D = ∪Ti ⊂ S.
I am interested in cases where the territory is partition into a set of equal population districts, thus I introduce the following definition:
Definition 4
A valid districting is a set of nD disjoint districts {Di} for 1 ≤ i ≤ nD such that S = ∪i≤nD Di and −t ≤ |Di| −|Dj| ≤ t for 1 ≤ i, j ≤ nD and t ∈ ℝ.
The quantity nD is the total number of districts in S. I call t the population tolerance, which allows for variations in population between districts. Characteristically, I will take t ∼ 0.01 × PS/nD, such that differences are percent-level. The above definitions do not rely on the spatial distributions of voters. Including geometric data in the problem means imposing a relation between the territorial units (sets of voters), and notions of adjacency and connected, such that the set of territorial units form a connected territory. Such spatial relationships can be intuitively introduced via a lattice model, in which each territorial unit is associated to a single lattice site:
Definition 5
A lattice territory Sn is an n×n lattice on Z2 and a lattice territorial unit Ti, j is a lattice site (i, j) ∈ Sn, it is characterized by its population Pi, j ∈ ℕ. Thus, the total population is PSn = ∑(i, j) Pi, j.
Then, a district is simply a sub-lattice of the lattice territory Sn, and the definition of valid districting for lattice territories carries over from Definition 4.
Definition 6
A lattice district is a set of territorial units D = {Ti} ⊂ Sn; its population is P D = ∑(i, j)∈D Pi, j.
A lattice territory is ideal for my analysis, since the input and output are square matrices, which are easier to manipulate compared to a collection of graph theoretic node objects. Since henceforth I am concerned only with lattice models, when there is no ambiguity I will neglect the “lattice” prefix when referring to objects. Furthermore, for a lattice territory the concepts of adjacency and connectedness are intuitive:Definition 7
Territorial units at (i, j) and (k,l) are adjacent if i = k ±1, j = l xor j = l ±1,i = k.
Definition 8
A territorial unit T1 is reachable from T2 if there exists a sequence of adjacent territorial units beginning at T1 and ending at T2. A lattice district D is connected if any T ∈ D is reachable ∀Ti ∈ D.

Figure 2: A sample population distribution from my walker algorithm, where color intensity indicates population density.
Assigning a population value to each territorial unit T i, j ∈ S n defines a population distribution, however I want to consider population distribution which well model real world population spreads. In this work I focus on a quasi-Gaussian distribution of population much as would be appropriate in a large city in which the population is highly dense towards the center and becomes diffuse at large radial distances.
Realistic population models can be constructed on a lattice Sn with n ∈ Zodd. To approximate a Gaussian population spread with random fluctuation, I implemented a walker function (see e.g. Shiffman (2012)), as follows: I first designate a starting populating size PS = |Sn|, each element vi ∈ Sn takes a value in (−1,1), but I leave these values undetermined at this stage.
I designate the central lattice site (0,0). Then, to implement the walker function, I fix the starting distribution PT0,0 = PS and PTi, j = 0 for (i, j) ≠ (0,0), and the walker function assigns each voter v a fixed number of moves. In each step, each element v ∈ Sn will move from its current unit to any adjacent units with equal probability, with the restriction that the element remains within Sn. Once an element v has taken its prescribed number of moves, it remains in its terminal unit. The move counts across all constituents follow a normal distribution centered at the number of moves needed to reach a corner from the origin. The population spread due to this walker algorithm well approximates a two dimensional Gaussian distribution; an example is shown in Figure 2.
Modeling Elections on the Lattice
With a working lattice model of population distributions, I now introduce a flexible manner of introducing a partisan bias within the population and defining the premise of voting and electoral events.
Definition 9 The net territory vote (or popular vote) of a territory is NS:= ∑v∈Sv.
We assume all voters cast ballots, so each v > 0 corresponds to a single vote cast for the red party with probability v ∈ (0,1). Conversely, each v < 0 corresponds to a vote cast for the blue party with probability |v|. I also assume that the gerrymanderer knows how individuals will vote with certainty, although this could be relaxed in future studies.
Definition 10
Red is said to win the popular vote in S if NS > 0; conversely, blue wins (red loses) the popular vote if NS < 0. A territory is called balanced if NS ≈ 0.
However, rather than the popular vote of the whole territory, what is typically most important is the district-wise overall vote.
Definition 11
The net vote of a territorial unit is NT= ∑v∈T v. Similarly, the net vote of district D is ND = ∑Ti∈D NTi= ∑v∈Dv.
Definition 12
I say that red wins the district vote for district Diif NDi> 0; conversely, I say that blue wins (red loses) the district vote if NDi < 0. A district is called red-safe if NDi > w, where w ∈ Z is called the vote tolerance (conversely for blue-safe).
Without loss of generality, I let the gerrymanderer’s party (the proponent) corresponds to positive extremity:
Definition 13
The proponent (opponent) is the party which benefits (loses) from gerrymandering. A territorial unit T is a proponent unit if NT > 0, an opponent unit if NT < 0, or neutral if NT = 0.
Hence the gerrymanderer favors the v > 0 voters, and the ‘positive’ or ‘red’ party.
Since elections are dynamic and inherently uncertain, the gerrymanderer risks losing if they plan to win a district by only a single vote. Hence, the vote threshold w ensures that the gerrymanderer’s party wins a given district with a minimum margin of votes. I typically take w ∼ 0.01×PS/nD, where nD is the number of districts. One could also define wi district-by-district, such that the requirement is weaker or stronger depending on the demographics of the district.
The distinction between the district vote and the popular vote implies that a given party can lose the latter, while securing the most districts. Typically the most important outcome is the number of districts won by each party. Thus, gerrymandering fundamentally exploits the differences between the local and global properties of distributions.
Modeling Voter Preference Distribution
I now introduce a procedure for generating smooth distributions of voter preferences. I implement voter preference in terms of a number of specified points of peak partisan bias ‘sources’, with voter preference falling towards neutrality away from these peaks. Using an analogy to the theory of electrostatic potentials and inverse power laws, I define sources of partisan bias per the properties of point charges as follows.
Definition 14
A source point is a pair E = ((i, j), e) characterized by its location (i, j) ∈ Sn and magnitude e ∈ R of the source. I require that any set of sources {Ei} gives |NTk| ≤ 1 ∀Tk ∈ Sn. I call E a red source for e > 0 and a blue source for e < 0.
Source points are located at arbitrary lattice sites, and the voter preference at a given territorial unit T is a function of the distance d from these source points, following a 1/d power law:
Definition 15
The vote contribution ∆Tk,l from a source point E((i,j),e) to the net vote of territorial unit Tk,l, where (i, j) and (k,l) are separated by a distance d(Ti, j,Tk,l) is

I take a simple euclidean definition of the distance

This implies that the vote contribution from a given source falls linearly with distance d from the source. This will be sufficient for my purposes, however, in principle one could study other power laws or, indeed, consider sources each with different d dependencies.



Figure 3: Voter bias distributions with two source points.
Note that each source E influences all lattice points in Sn. Moreover, the net vote of the territorial unit Ti, j coincident with the source point Ei, j is not simply the magnitude of the source e but rather includes contributions from other sources. Because of the 1/d power law, the source points typically represent local maxima of the voter preference, with sign(e) indicating the favored party. It should also be highlighted that in principle two source points E1, E1 could be located at the same lattice site, say E1 = ((i, j), e1) and E2 = ((i, j), e2), however in this case the two sources can always be replaced with a single source as follows:
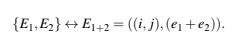
Benchmark Models
In a sample execution, I select the territorial units immediately left and right of the origin (0,0) to serve as blue and red source points, respectively. Specifically, I consider a set of two sources {EB, ER} with EB = ((1,0),−1) and ER = ((−1,0),1). The combination of the symmetric quasi-Gaussian population distribution, as shown in Figure 2, and the sources {EB, ER} produces the voter preference distribution shown in Figure 3. The red/blue intensity indicates the magnitude of the net voter preference NTi ∈ (−1,1), with the center of these colored regions corresponding to the positions of the two source points EB and ER. In my subsequent analysis I shall consider two specific benchmark models with certain source point distributions. Table 1 specifies these benchmark models:

Table 1: Benchmark models with 2 or 4 sources for a 21×21 lattice territory. A dash indicates that a given source is not included in a given model.
Note that the partisan spread of model #1 is illustrated in Figure 3 and models #2- #5 are shown in Figure 4. These models demonstrate that the code can implement a wide variety of voter distributions.

Figure 4: Visualization of voter bias distributions for models #1 and #2.
The Friedman Holden Packing Strategy
There are two fundamental strategies in algorithmic gerrymandering: packing and cracking. First, a gerrymanderer can dilute the voting power of the opponent party either by packing the most concentrated opponent-voting subpopulations into a small number of districts. Second, one can crack the most concentrated opponent population into several districts so that the most concentrated or extreme voting base for the opponent party never gains a majority. A strategic application of voter packing underlies the approach of Friedman & Holden (2008).
Friedman & Holden (2008) consider a pseudo-normal voter extremity distribution and generated districts by partitioning the bell curve of the voting population by extremity. For the example in Fig. 5., the gerrymanderer favors the red party (v > 0), which corresponds to positive extremity. The first district is formed by joining the most extreme subpopulations, i.e., the bell curve tails, so that i) their combined population is approximately the average district population, and ii) the right tail is sufficiently larger than the left tail. The latter condition signifies that the extreme right-party voters are large enough in quantity to override the extreme left-party vote in their district.
This process will, in essence, “waste” the opponent’s strongest voting population in a district it cannot likely win. This process is repeated on the subsequent districts and the final district is composed of the remaining population around the median. By construction, the last district will be comprised of mostly moderate voters and, for balanced territories, is typically won by the opponent party.

Figure 5: Example of the method from Friedman & Holden (2008). The x-axis indicates voter extremity E for two parties, assuming that voter bias has a pseudo-normal distribution. The bell curve is partitioned into five districts so that the results favor the E > 0 party.
This approach has a number of merits but suffers from the lack of spatial considerations. The Friedman-Holden method equates to unrestricted “cherry picking”: the gerrymanderer has the freedom to select scattered population chunks for placement in the same category, as I demonstrate shortly. Notably, if even a single district is disconnected, the districting plan is typically legally prohibited. A useful measure of failure is the number of connected components of each district:
Definition 16
A connected component C ⊆ D is a (non-empty) set of Ti ∈ D such that for Ti ∈C then Tj ∈C if and only if Ti is reachable from Tj.
A district can be decomposed into connected components: D = ∪i≤rCi, where r is the number of connected components. If any territorial unit in D is reachable from all other territorial units in D, then C = D and r = 1, so D is connected. The number of connected components is important for the analysis of the spatial distributions arising through the algorithms studied.
Implementing Friedman and Holden’s Algorithm
Friedman & Holden (2008) outline a packing strategy which ignores the spatial data of the voter distribution. Here I first reformulate the strategy of Friedman & Holden (2008) for generating districts in terms of an algorithmic approach applied to a lattice population model, but without reference to the spatial distribution of voters. By neglecting spatial data during the redistricting process, but tracking the positions of the units in each district, I can assess the connectivity of the districts constructed via FH packing.
Recall that voting districts are legally required to have approximately equal population. I implement this requirement via the population threshold parameter t introduced in Definition 4 and define:
Definition 17
The target population PD± := (PS/nD ± t) for nD the designated number of districts.
This requirement ensures that all districts have approximately equal populations. The value of PD ± is computed before the algorithm is executed and used as an input. For my studies of redistricting, I take t = 0.05×PS/nD, unless stated otherwise.
I assume nD ~ ϭ(1), and as a characteristic value I use nD= 5. The algorithm iteratively assigns single unassigned units to a district, one district at a time.
Definition 18
An unassigned unit is a territorial unit not yet assigned to a district. I denote the set of unassigned units U.
Once the algorithm is satisfied with the composition of a given district it proceeds to form the next district, until all nD districts are formed. Specifically, each district should satisfy the population threshold
P D− ≤ P Di ≤ P D+
and all district except the last (which much have an opponent bias if the vote is balanced) should satisfy the vote threshold
NDi > w.
For an Sn territory I initially have n 2 unassigned territorial units, which I enumerate {Ti} for 1 ≤ i ≤ n 2 and nD(empty) districts. Each T i stores the values of N Ti to evaluate how many more votes for a particular party are expected from each Ti. The sign of NTi indicates the net partisan affiliation of the territorial unit. As territorial units are assigned to districts by the algorithm, they are deleted from U.

Editor's note: below, T^1 indicates
I implement the FH packing algorithm by first sorting the territorial units in order of decreasing net vote N Ti , using a quicksort method [2], and I relabel the elements of the ordered set {Tˆ i } with 1 ≤ i ≤ n 2 . Thus Tˆ 1 corresponds to the strongest unit vote for the opponent (blue) party, similarly Tˆ n2 is the strongest unit vote for the proponent party. More generally, the strongest unassigned opponent unit is T i ∈ U such that N Ti ≥ N Tj for all T j ∈ U, or equivalently it is Tˆ i with i the smallest integer index in the set U. Conversely, Tˆ i with i the largest integer index in U is the strongest unassigned proponent unit.
The algorithm takes an unformed district, which is initially Di {}, and iteratively adds first the strongest the unassigned proponent unit followed by the strongest the unassigned opponent units until PD > PD−. The algorithm then calculates the district vote NDi and compares it to the vote threshold w. If NDi > w and PD < PD+ then the district is complete and the algorithm repeats this process for the remaining districts, with the exception of the last district.
It may be the case, however, that in forming a given district once the district satisfies PD > PD−, the district vote is calculated to be less than the vote threshold NDi < w. In this case the algorithm adds the strongest remaining unassigned proponent units until NDi > w, at each step checks that PD < PD+. Once the district vote is sufficiently large, the district is complete. Additionally, when the population limit is exceeded PD > PD+ my algorithm will remove the last united added and try the next in the ordered list until it identifies an addition to the district that does not violate the population limit. For large vote thresholds w or small population thresholds t, this districting algorithm may fail (i.e. no district satisfies simultaneously population and vote thresholds), but this is rarely a problem for percent-level w and t.
As alluded to above, the criteria for the last district must be different. If the popular vote is balanced vote, as I assume here, then it is impossible to arrange for all districts to favor the proponent party. Thus, it is expected that for the nDth district that NDn < 0. The final district is identified with the remaining unassigned territories after construction of the (nD − 1)th district. By design, the final district is primarily comprised of moderate voters. The only requirement on the final district is that it satisfies the population constraint PD− ≤ PDn ≤ PD+. In the case that PDn > PD+, the proponent-favoring population units on the exterior of the final district will be transferred to adjacent districts. If PDn < PD−, then the opponent-favoring population units in other districts and adjacent to the final district will be transferred to the final district.
Impact of Friedman and Holden Packing Method
Before examining whether the districts of the Friedman and Holden method are connected, I first shall look to quantify what degree of advantage this gerrymandering procedure gives to the proponent party comparing to a non-partisan model of districting. To assess the impact of gerrymandering via the Friedman and Holden method I take a set of voters and associate each to territorial units which are lattice sites of 21×21 lattice S21, with total population∗ PS ≈ 4700 (up to 0.5% fluctuations). This results in a set of territorial units with fixed populations and partisan biases {Ti}.
I then implement the Friedman and Holden algorithm on the set of voters (which neglects all spatial data) and partition the territory into nD = 5 districts. Following the Friedman-Holden method, I order the units {Ti} by extremity and assign units with opposite partisan biases to districts {Di} in a manner that benefits the proponent party and gives approximately equal population districts. Since the walker function introduces random fluctuation in the approximately Gaussian population distribution, each run returns a different redistricting. Thus I can assess the impact of gerrymandering for a given set of source points via a statistical approach by multiple runs of the algorithm.
Specifically, I generate a set of different redistricting plans on 30 different S21 lattice population models with 5 benchmark source point placements (as shown in 3 & 4) and partition the territory into nD = 5 districts. I calculate the average net vote per district NDi and the predicted number of safe proponent districts (#safe). In Table 2, I show the average net vote NDi in each district (where the districts are enumerated by order of construction) following redistricting via the FH method and averaging over 30 runs.

Table 2: Average net vote per district following redistricting via the FH method.

I want to compare these results to some “fair” partition of the population. Since the population has been generated to approximate a two dimensional spherically symmetric Gaussian distribution, that means that any spherically symmetric partition of the population which does not take into account the partisan bias can be considered a non-partisan districting. Specifically, I shall construct a non-partisan nD = 5 districting by allocating the central cells to District 1 and then partitioning the set of territorial units not assigned to District 1 to create Districts 2-5. I choose to partition Districts 2-5 by simply drawing the district lines along x = 0 and y = 0 and assigning the territorial units on the borders to the adjacent district in the clockwise direction. The size of District 1 is fixed such that the 5 territories have approximately equal populations, up to 5% deviations. The resulting districts are illustrated in Figure 6.
To assess the impact of gerrymandering, I compare predicted election results for the case of aggressively gerrymandered districts (as determined by my algorithm) to the net vote for the symmetric districts outlined above. I generate 30 population distributions on S21 and calculate both the average net vote per district NDi and the predicted number of safe proponent districts (#safe), the results are shown in Table 3.

Table 3: Average net vote per district for idealized symmetric districts.
From comparison of Table 2 and 3 it is clear that FH packing significantly impacts the electoral outcome. However, as I show in the next section, the districts constructed are generally disconnected and therefore typically legally prohibited.
Connectivity of Friedman and Holden Districts
Since the Friedman-Holden method includes no spatial data, one might expect disconnected districts; however, I wish to quantify the failure of this approach. I take the districts constructed in Table 2 and output the assignments of the territorial units and identify the number of connected components in each district. For illustrative purposes I show one (of the 30) district compositions output by the algorithm, immediately one observes that the districts are highly disconnected in all cases.
To quantify this statement, I take the outputs of the 30 runs of FH packing on S21 generated previously and calculate the mean number of connected components for each district (labelled D2 to D5) and the mean over all districts for the 5 benchmark source point models. The results are displayed in Table 4.

Table 4: Number of connected components for districted created by FH method.
I find that the approach of Friedman & Holden (2008) typically outputs districts with ∼ 4 components. Importantly, disconnected districts are legally prohibited, thus, while the Friedman-Holden method is simple and easy to implement, it is too simplistic to give a realistic model of redistricting. It is critical that algorithmic approaches take into account the spatial distribution of voters.
Packing with Spatial Restriction
In this section, I outline algorithms that gerrymander voter distributions on a lattice in a manner that strongly favors the proponent party and give connected districts. As stated in the introduction, I study two specific packing strategies, I call these “Extremal Packing” and “Friedman-Holden Packing”. I start be outlining algorithms to implement these two strategies effectively on a lattice.
Spatially Restricted Friedman-Holden Packing
As seen in the previous section without taking into account the spatial distribution of voters FH packing leads to highly disconnected districts. In this section I outline a modification to the FH packing algorithm to include geographical data, I call this Spatially Restricted Friedman-Holden (SRFH) Packing. This districting algorithm starts each district by taking the strongest opponent and proponent unassigned units and forming a path between them (which necessarily includes moderate voters). The algorithm then successively adds highly polarized units of both parties which are adjacent to the forming district, until it satisfies the population threshold and the net vote favors the proponent party.
I first discuss the general construction of districts, with the exception of the final district. Suppose there are x unassigned territorial units {Ti} for 1 ≤ i ≤ x (for District 1: x = n2). Similar to the FH algorithm, the first step is to sort, via quicksort, the unassigned units in order of decreasing net vote NTi and relabel the ordered set {Tˆi} with 1 ≤ i ≤ x. To form each new district the algorithm connects the two most oppositely polarized unassigned units (i.e. Tˆ1 and Tˆx) via the shortest path that avoids all existing districts. I use a standard Grassfire algorithm Bium (1964) to remove assigned units when determining the shortest path. In all of the cases I consider, the total population of the path between Tˆ1 and Tˆx is well below the target population PD±.

Figure 7: Left: a hypothetical example of the most extreme proponent and opponent units. Center: the shortest path through unassigned territory between the extreme endpoints. Right: the set of population units (orange) considered for addition to the district.
While PDi < PD−, the algorithm will repeatedly add to the collection the most extreme territorial unit that is unassigned and adjacent to the set. If the net vote of the district does not sufficiently favor the proponent party, as determined by a vote tolerance parameter w (cf. Def. (12)), then the algorithm will successively add proponent units to the collection. Once the net vote favors the proponent, the algorithm adds opponent units to balance the vote. After adding c units to a given district, the algorithm fixes the district when ∑i≤c+1 PTˆi > PD−. It then checks that ∑i≤c PTˆi < PD+. If this check fails, the final unit added, Tc, is replaced with an alternative adjacent unit, until the above is satisfied. After a connected set is validated as a district, the algorithm recurs on the remaining sorted list of territorial units. In the end, I expect the algorithm to produce districts in order of decreasing polarity, with the proponent vote being stronger than the opponent vote.
The remaining unassigned units after the construction of nD − 1 districts are typically disconnected, thus one can not simply identify the remaining voters with the final district. Producing a valid redistricting requires some further manipulation of the districts formed, as I discuss in the next section. This is a feature of all algorithms which do not track the subsequent implications to later districts, whilst assigning territorial units.
A Saturation Packing Algorithm
A simple modification of the SRFH Packing approach allows gerrymanderers to secure more districts to vote their way. The rationale behind further improving the SRFH Packing algorithm is that the gerrymanderer cannot reasonably ensure a proponent win in all of the districts, as long as the territory net vote is balanced. Specifically, the last district produced by the Friedman Holden approach consistently favors the opponent party. Since the proponent party is not expected to win in this “throw-away” district, populating this district with the strongest opponent voting base (instead of moderate voters) should allow for more effective gerrymandering.
The Saturation Packing algorithm packs extreme opponent voters into a single compact district. Before this first district is constructed, each population unit is assigned a priority value based on its net vote and its average distance from proponent source points.

Once all priorities are assigned, the algorithm sorts the list of population units in order of decreasing priority. Because negative values of NT indicate a net vote for the opponent, the population unit with the highest positive priority at the beginning of the sorted list is added to the collection D1 that will eventually become the first district. Then, the algorithm searches over all population units adjacent to D1 and adds the highest priority unit to D1. This last process is repeated until ∑T∈D1 PT > PD−. After this first district is constructed via the Saturation Packing algorithm, all subsequent districts are created using the SRFH Packing algorithm.
Sample executions
In Figure 8, I present six example outputs of my working code in which I partition a 21×21 lattice into five districts. The left most panel shows the voter distribution (two cases: top and bottom) and the five panels to the right show the gerrymandered districts output by the code. My code is most effective for populations of oppositely extreme partisanship situated in close proximity to one another, an example of which for nD = 5 is shown in the lower panels of Figure 8.
In both cases of Figure 8, districts 1-3 illustrate the pairing of the most highly partisan subpopulations such that the proponent vote overpowers the opponent vote, as advocated in Friedman & Holden (2008). The lower example fixes the two partisanship source points to be proximal and with maximum extremity, in order to maximize the connectedness of the most polar districts. Even with this idealized setting, the outer districts are highly non-compact. This suggests that a raw algorithmic approach of packing and cracking might be easily detected, or constrained, via appropriate measures.

Figure 8: Districting results for sample voter extremity distributions. The same Gaussian population distribution was used in both samples, and the vote was balanced. In both cases, the proponent party, corresponding to the color red, sufficiently wins the popular vote in three of the five districts.
Conclusion and Extensions
I have presented a number of tools for studying gerrymandering and used these to examine a number of important issues. Specifically, a lattice model for population distributions was developed, which allows for independent assignments of partisan bias spreads, and I proposed an algorithm to partition lattice models into aggressively gerrymandered, equal-population, connected districts.
I used my lattice model to show that the method of Friedman & Holden (2008) is unrealistic since it generally leads to disconnected (thus invalid) districts. However, the techniques of packing and cracking remain central tools for gerrymandering, and I used these in the construction of my own algorithms. Subsequently, I employed the outputs of my gerrymandering algorithm to quantify some general properties of gerrymandering. One of my immediate observations was that gerrymandering is seemingly far more effective in cases where the most partisan voters of both parties are in close proximity. Moreover, I used my code to empirically demonstrate that gerrymandering provides a clear advantage to the proponent party and that my gerrymandered territories generally fail isoperimetric quotient tests. Moreover, this shows that such computational tools can provide a powerful approach to quantitatively study political gerrymandering.
In future work, it would be interesting to explore certain generalizations of the above algorithms, for instance, the prospect of incorporating third-party candidates and nonvoting electors. Furthermore, my current algorithm assumes complete knowledge about the population spread and expected vote outcomes, but in reality, a gerrymanderer has imprecise information about these distributions, which leads to uncertainty in the voter preference distributions. Voter uncertainty can be implemented by replacing v ∈ (−1,1) with a confidence interval v0 ± c, where v0 is the expected value, such that v = (v0 − c, v0 + c) ⊂ (−1,1). One might also implement ‘voter shocks’ to model swings in the popular vote by ϭ(10%) after redistricting is complete, as discussed in Friedman & Holden (2008). Both of these extensions directly affect the required vote tolerance w, since if w during redistricting is not sufficiently large, the proponent party may lose the election.
The reassignment of power to the electorate is the fundamental strength of representative democracies. Political gerrymandering, if left unchecked, threatens to undermine our democratic systems. Since gerrymandering issues can be formulated as well-stated mathematical and computational problems, one can develop tools and tests to identify and inhibit these practices. Towards this goal, I have developed in this work a lattice model of realistic voter distributions with which to study the process of gerrymandering. I used my lattice models to show that the highly aggressive approach of Friedman & Holden (2008) can be effectively constrained by requiring districts to be connected. Furthermore, I constructed an aggressive gerrymandering algorithm that accounts for the spatial distribution of voters and demonstrated that this approach can be effectively constrained by compactness requirements. Notably, while connectivity is legally mandated, compactness is not. Thus, my work provides quantitative support in favor of implementing some legally mandated compactness requirement for redistricting to inhibit these aggressive gerrymandering strategies.
I am currently extending this research on gerrymandering algorithms by developing a fair districting algorithm. Indeed, the ultimate solution to the gerrymandering problem is not just a detection method but a more equitable districting alternative. It has been shown that no partitioning of a state population into a finite number of voting districts can be entirely fair. Even though election fairness is limited, I can still maximize this fairness by employing a genetic algorithm. Borrowing from the principles of evolution and natural selection, this genetic algorithm evolves a population of increasingly equitable districtings over many generations. By analyzing the throughput of the genetic algorithm, I can better understand the largely uncharted process of determining fair representation for a fair democracy.
∗The typical population of U.S. congressional districts is 700,000; my results can be rescaled accordingly if desired.
References
[1] Benisek v. Lamone, No. 13-cv-03233-JKB, 2017 WL 3642928 (D. Md. Aug. 24, 2017), appeal docketed, No. 17-333 (U.S. Sept. 1, 2017).
[2] C. A. R. Hoare Algorithm 64: Quicksort, Comm. ACM. 4 (7): 321 (1961).
[3] C. Puppe, A. Tasnadi, Axiomatic districting, Social Choice and Welfare 44.1 (2015) 31.
[4] C. Puppe, A. Tasnadi Optimal redistricting under geographical constraints: Why “pack and crack” does not work Economics Letters 105.1 (2009): 93-96.
[5] C. P. Chambers and A. D. Miller, A Measure of Bizarreness, Quarterly Journal of Political Science 5 (1) (2010), 27-44.
[6] D. D. Polsby, R. D. Popper, The Third criterion: Compactness as a procedural safeguard against partisan gerrymandering, Yale Law and Policy Review, 9 (1991), 301.
[7] D. Shiffman, The Nature of Code: Simulating Natural Systems with Processing (2012), ISBN-13: 9780985930806.
[8] E. C. Roeck, Jr., Measuring the compactness as a requirement of legislative apportionment, Midwest Journal of Political Science, 5 (1961), 70-74.
[9] H. Bium, A transformation for extracting new descriptions of shape, Symposium on Models for the Perception of Speech and Visual Form, MIT Press (1964).
[10] H. P. Young, Measuring the Compactness of Legislative Districts, Legislative Studies Quarterly Vol. 13, No. 1 (1988), pp. 105-115
[11] J. E. Schwartzberg, Reapportionment, gerrymanders, and the notion of compactness, Minnesota Law Review, 50 (1966), 443-452.
[12] J. Hodge, E. Marshall, and G. Patterson, Gerrymandering and Convexity, The College Mathematics Journal Vol. 41, No. 4 (2010), pp. 312-324
[13] J. N. Friedman, R. T. Holden, Optimal Gerrymandering: Sometimes Pack, But Never Crack, American Economic Review (2008), 98:1, 113-144.
[14] J. Oxtoby, Diameters of Arcs and the Gerrymandering Problem, The American Mathematical Monthly, Vol. 84, No. 3 (1977), pp. 155-162
[15] K. Sherstyuk, How to Gerrymander: A Formal Analysis, Public Choice 95, (1998) 27.
[16] Miller v. Johnson, 515 U.S. 900 (1995).
[17] M. Altman and M. McDonald, BARD: Better Automated Redistricting, Journal of Statistical Software, Articles 42 (2011) 4.
[18] N. Apollonioa, et al. Bicolored Graph Partitioning, or: Gerrymandering at its Worst, Discrete Applied Mathematics, Volume 157, Issue 17, 28 (2009), 3601.
[19] Niemi, R.G., B. Groffman, C Calucci and T. Hofeller, Measuring compactness and the role of compactness standard in a test for partisan and racial gerrymandering, Journal of Politics 52:1155 (1990).
[20] Shaw v. Reno, 509 U.S. 630 (1993).
[21] Whitford v. Gill, 218 F. Supp. 3d 837 (W.D. Wis. 2016), prob. juris. postponed to hearing on the merits, 137 S. Ct. 2268 (2017).




